本文接2025-12-02发布的rust学习
字符串与切片
String和&str的区别
在其他语言中,字符串往往都是相当简单的内容,基本都是”hello world“,但是不能把同样的想法带到Rust,应当重视这个部分,否则会栽跟头
fn main() {
let my_name = "Pascal";
greet(my_name);
}
fn greet(name: String) {
println!("Hello, {}!", name);
}就比如这一段代码看似正常实际上就会报错
错误内容就是:函数需要一个String,但是却传进来一个&str类型的字符串
那么我们来看一下这两个的区别:
String是标准库里的堆分配、可增长、可修改、有所有权的字符串类型&str是堆程序中一段只读数据的不可变借用,没有所有权(因为是引用)
str则是上一篇里就介绍的字符串字面量,他不可以修改,船舰后就写死在栈里,和常量一样
重点记忆的是:
字面量多半是&str,要堆上可变字符串就用String
什么是切片slice(以字符串为例)
切片就是对集合中连续一部分元素的引用,不是整个集合
对字符串而言,切片就是对String类型中某一部分的引用,看起来长这样
let s = String::from("hello world");
let hello = &s[0..5];
let world = &s[6..11];字符串切片语法是:&s[start..end],讲中文就是[开始索引..终止索引]
值得注意的是,开始索引是切片中第一个元素的索引位置,而终止索引是最后一个元素后面的索引位置,也就是说,这是一个左闭右开区间
对字符串切片时,必须落在UTF-8边界上,否则会panic
就比如”中国人“这三个字,每个汉字三个字节,想要取这个”中“字,完整应该是&s[0..3],如果用&s[0..2]就会崩溃
如果像索引从0开始,可以不加这个0:&s[..3]
切片+借用规则
fn first_word(s: &String) -> &str 看这句代码,他说明:
借用一个
String,不拿所有权返回它里面的一段
&str切片
再来看这段错误代码
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s);
s.clear(); // error!
println!("the first word is: {}", word);
}
fn first_word(s: &String) -> &str {
&s[..1]
}这段会报错的问题就是:违反了不能同时存在可变与不可变借用
因为claer需要清空改变String,因此他需要一个可变借用,这个方法声明实际上是这样的pub fn clear(&mut self),参数是对自身的可变借用
总结一句话:有切片在用,就不能随便改原字符串
其他切片
不仅仅字符串有切片,其他集合类型也有,例如数组:
let a = [1, 2, 3, 4, 5];
let slice = &a[1..3];
assert_eq!(slice, &[2, 3]);这个数组切片类型是&[i32],数组切片和字符串切片工作方式一样
字符串字面量就是切片
"Hello,world!"的类型就是&str,所以这两种写法等价
let s = "Hello, world!";
let s: &str = "Hello, world!";它指向的是可执行文件中的一段只读内存,所以字面量是不可变的
所有 "..." 字面量,都可以当作 &str 切片看
String/&str之间怎么互相转换
&str->String
String::from("hello,world")"hello,world".to_string()
String->&str
String类型转为&str需要取引用
fn main() {
let s = String::from("hello,world!");
say_hello(&s);
say_hello(&s[..]);
say_hello(s.as_str());
}
fn say_hello(s: &str) {
println!("{}",s);
}记住一点:要拥有它就变成String;只借用它就保持/转成&str
字符串索引:为啥不能用整数下表直接访问String
String底层是Vec<u8>(字节数组),而不是定长char数组
就比如说,英文"hello"长度五个字节,中文"你好“实际上是6个字节
索引s[0]得到的只是第一个字节,不是一个完整的字符,语义非常奇怪,所以Rust直接禁止String的整数索引
更深一层:同一个字符串可以有多种“视角”——字节序列、
char序列、按人类语义的“字形簇”(比如梵文例子)。再加上字符边界不规则,想保证
s[i]是 O(1) 也做不到,所以干脆不让你这样用。
上面的部分总结就一句话
用 String 持有,用 &str 借用;用 &s[a..b] 取一段;记住 UTF-8 边界 + 借用规则,不要直接用整数索引字符串。
⭐操作字符串
1. 追加(push/push_str)
作用:在尾部加东西,修改原String(前提必须要mut关键字)
push(ch:char):追加一个字符push_str(s:&str):追加一个字符串切片
以上两种方式都是在原有字符串上进行修改,不会返回新字符串
fn main() {
let mut s = String::from("Hello ");
s.push_str("rust");
println!("追加字符串 push_str() -> {}", s);
s.push('!');
println!("追加字符 push() -> {}", s);
}运行结果:
追加字符串 push_str() -> Hello rust
追加字符 push() -> Hello rust!
总结:往后面加 → push / push_str,原地改,所以要 mut
2. 插入(insert / insert_str)
作用:在中间插东西(按照字节位置下标,越界会发生错误,必须mut)
insert(idx,ch):在位置idx处插入一个charinsert_str(idx,s):在位置idx处插入一个&str
fn main() {
let mut s = String::from("Hello rust!");
s.insert(5, ',');
println!("插入字符 insert() -> {}", s);
s.insert_str(6, " I like");
println!("插入字符串 insert_str() -> {}", s);
}运行结果:
插入字符 insert() -> Hello, rust!
插入字符串 insert_str() -> Hello, I like rust!
总结:下标按 字节 算,中文要小心 UTF-8 边界
3. 替换(replace/replacen/replace_range)
替换有三种方式,依次来讲
3.1 replace
作用:接收两个参数,第一个是要被替换的字符串,第二个是新的字符串;把所有匹配字符串都替换掉,返回新的String,不改原字符串,适用于String/&str
fn main() {
let string_replace = String::from("I like rust. Learning rust is my favorite!");
let new_string_replace = string_replace.replace("rust", "RUST");
dbg!(new_string_replace);
}运行结果:
new_string_replace = "I like RUST. Learning RUST is my favorite!"
3.2 replacen
作用:接收三个参数,前两个和replace一样,第三个表示替换的个数;只替换前N个匹配字符串,返回新的String,不改原字符串,适用于String/&str
fn main() {
let string_replace = "I like rust. Learning rust is my favorite!";
let new_string_replacen = string_replace.replacen("rust", "RUST", 1);
dbg!(new_string_replacen);
}运行结果:
new_string_replacen = "I like RUST. Learning rust is my favorite!"
3.3 replace_range
作用:接收两个参数,第一个是要替换字符串的范围(Range),第二个参数是新的字符串;替换掉一定范围内匹配的字符串,直接操作原来的字符串,不会返回新的字符串,所以还要使用mut关键字,仅使用于String类型
fn main() {
let mut string_replace_range = String::from("I like rust!");
string_replace_range.replace_range(7..8, "R");
dbg!(string_replace_range);
}运行结果:
string_replace_range = "I like Rust!"
上述三个方法总结:
要返回新字符串就用replace/replacen
想修改原字符串用replace_range(要mut关键字)
4. 删除(pop / remove / truncate / clear)
上述四种方式都只适用于String,都会直接修改原字符串
4.1 pop——删除并返回字符串最后一个字符
返回值是一个Option类型,如果字符串为空,返回None
fn main() {
let mut string_pop = String::from("rust pop 中文!");
let p1 = string_pop.pop();
let p2 = string_pop.pop();
dbg!(p1);
dbg!(p2);
dbg!(string_pop);
}运行结果:
p1 = Some(
'!',
)
p2 = Some(
'文',
)
string_pop = "rust pop 中"4.2 remove——删除并返回字符串中指定位置的字符
只接收一个参数,表示该字符起始索引位置;存在返回值;按照字节处理字符串,如果参数不合法会发生错误
fn main() {
let mut string_remove = String::from("测试remove方法");
println!(
"string_remove 占 {} 个字节",
std::mem::size_of_val(string_remove.as_str())
//这里的::是rust里的路径分隔符,就是为了写一个完整的路径
//读出来就是”调用标准库里mem模块里的size_of_val这个函数
);
// 删除第一个汉字
string_remove.remove(0);
// 下面代码会发生错误
// string_remove.remove(1);
// 直接删除第二个汉字
// string_remove.remove(3);
dbg!(string_remove);
}因为删除的是中文,一个汉字三个字节,所以索引值为1不合法,会发生错误
运行结果:
string_remove 占 18 个字节
string_remove = "试remove方法"4.3 truncate——删除字符串中指定位置开始到结尾的全部字符
和上面类似,只接收一个参数,表示该字符起始索引位置;这个方法没有返回值,按照字节处理字符串,如果位置不合法也会发生错误
fn main() {
let mut string_truncate = String::from("测试truncate");
string_truncate.truncate(3);
dbg!(string_truncate);
}运行结果:
string_truncate = "测"4.4 clear——清空字符串
删除字符串中的所有字符,相当于truncate(0)
fn main() {
let mut string_clear = String::from("string clear");
string_clear.clear();
dbg!(string_clear);
}运行结果:
string_clear = ""5. 连接字符串(+/+=/format!)
5.1 +/+=
当使用+这个方法时,实际上就是用std::string 标准库中的 add() 方法
add(self, s: &str) -> String
左边:String(会被move)
右边:必须是&str(&String会自动变成&str)
+会返回一个新的字符串,变量声明可以不需要mut关键字
+=则是在原字符串上做修改,需要mut关键字
fn main() {
let string_append = String::from("hello ");
let string_rust = String::from("rust");
// &string_rust会自动解引用为&str
let result = string_append + &string_rust;
let mut result = result + "!"; // `result + "!"` 中的 `result` 是不可变的
result += "!!!";
println!("连接字符串 + -> {}", result);
}运行结果:
连接字符串 + -> hello rust!!!!
5.2 format!
这种方法使用于String和&str,使用方式和print!类似
fn main() {
let s1 = "hello";
let s2 = String::from("rust");
let s = format!("{} {}!", s1, s2);
println!("{}", s);
}运行结果:
hello rust!字符串转义
我们可以通过转义的方式 \ 输出 ASCII 和 Unicode 字符
fn main() {
// 通过 \ + 字符的十六进制表示,转义输出一个字符
let byte_escape = "I'm writing \x52\x75\x73\x74!";
println!("What are you doing\x3F (\\x3F means ?) {}", byte_escape);
// \u 可以输出一个 unicode 字符
let unicode_codepoint = "\u{211D}";
let character_name = "\"DOUBLE-STRUCK CAPITAL R\"";
println!(
"Unicode character {} (U+211D) is called {}",
unicode_codepoint, character_name
);
// 换行了也会保持之前的字符串格式
// 使用\忽略换行符
let long_string = "String literals
can span multiple lines.
The linebreak and indentation here ->\
<- can be escaped too!";
println!("{}", long_string);
}某些情况下,想要保持字符串原样,不要转义
fn main() {
println!("{}", "hello \\x52\\x75\\x73\\x74");
let raw_str = r"Escapes don't work here: \x3F \u{211D}";
println!("{}", raw_str);
// 如果字符串包含双引号,可以在开头和结尾加 #
let quotes = r#"And then I said: "There is no escape!""#;
println!("{}", quotes);
// 如果字符串中包含 # 号,可以在开头和结尾加多个 # 号,最多加255个,只需保证与字符串中连续 # 号的个数不超过开头和结尾的 # 号的个数即可
let longer_delimiter = r###"A string with "# in it. And even "##!"###;
println!("{}", longer_delimiter);
}上面这些我看的不太懂,扩展一下知识:
字符、ASCII、Unicode 分别是什么
字符(character)
字母、数字、标点、汉字甚至emoji表情,这些都是字符
但是电脑里只能存0/1,所以需要一套规则把“字符-数字-字节”对应起来,这个规则就叫字符编码
ASCII
这时最早的一套编码标准
它只规定了128个字符(0-127):
英文字母A-Z/a-z
数字0-9
常见标点
加上一些控制符(换行、回车等看不见的字符)
每个ASCII字符用1个字节的低7位表示
简单理解来说,就是只够英文用,什么汉语、日文表情都不够
Unicode
这是一个大一统标准
世界上所有的文字、符号都给一个统一的编号,叫做码点(code point),就像“中”这个字就写成U+4E2D
编号只是抽象概念,落到字节上,还要有具体的编码方式:
常见:UTF-8、UTF-16、UTF-32
Rust字符串默认用UTF-8编码
Unicode是个巨大的全集,ASCII的0-127也是它的一部分
学到这里,我发现我学这个并没什么用,因为这tm是编译器干的事...
元组
元组是由多个类型组合在一起的复合类型
元组的长度是固定的,元组中的元素顺序也是固定的
创建元组语法:
fn main() {
let tup: (i32, f64, u8) = (500, 6.4, 1);
}变量tup被绑定了一个元组值(500,6.4,1),这个元素类型是(i32, f64, u8)
元组就是把多个类型用括号括在一起
可以使用模式匹配或者.操作符来获取元组中的值
用模式匹配解构元组
fn main(){
let tup = (500, 6.4, 1);
let (x,y,z) = tup;
println!("这个y的值是{}",y);
}用.解构元组
模式匹配可以一次性把元组中的值全部或者部分取出来,但如果想要访问特定元素,就很麻烦
这时就需要使用.操作符来解构元组
fn main() {
let x: (i32, f64, u8) = (500, 6.4, 1);
let five_hundred = x.0;
let six_point_four = x.1;
let one = x.2;
}元组的使用场景
元组常用在函数返回值,可以使用元组返回多个值
fn main() {
let s1 = String::from("hello");
let (s2, len) = calculate_length(s1);
println!("The length of '{}' is {}.", s2, len);
}
fn calculate_length(s: String) -> (String, usize) {
let length = s.len(); // len() 返回字符串的长度
(s, length)
}这里函数接收了s1字符串的所有权,然后计算长度,最后把字符串所有权和字符串长度返回给s2和len变量
结构体
结构体和元组类似,都是由多种类型组合而成,不一样的是,结构体可以为内部的每一个字段起一个名称,无需再依赖字段的顺序访问解析,因此结构体更加灵活和强大
结构体语法
定义结构体:
一个结构体由三个部分组成:
通过关键字
struct定义一个清晰明确的结构体名称
几个有名字的结构体字段
创建结构体实例
为了使用上述结构体,需要创建User的结构体实例
let user1 = User {
active: true,
username: String::from("张三"),
email: String::from("lvdl0835@gmail.com"),
sign_in_count: 1,
};要注意的是:
初始化实例时,每个字段都需要进行初始化
初始化时的字段顺序不需要和结构体定义的顺序一样
访问结构体字段
let mut user1 = User {
active: true,
username: String::from("张三"),
email: String::from("lvdl0835@gmail.com"),
sign_in_count: 1,
};
user1.username = String::from("李四");通过.操作符可以访问结构体实例内部的字段值,也可以修改(前提是结构体实例声明为可变的,要有mut)
rust不支持将某个字段标记为可变
简化结构体创建
可以写一个构建函数简化创建
fn build_user(email: String, username: String) -> User {
User {
email: email,
username: username,
active: true,
sign_in_count: 1,
}
}这个函数接收两个参数email和username
struct User {
email: String,
username: String,
active: bool,
sign_in_count: u64,
}
fn build_user(email: String, username: String) -> User {
User {
email,
username,
active: true,
sign_in_count: 1,
}
}
fn main() {
let user1 = build_user(String::from("lvdl0835@gmail.com"), String::from("张三"));
println!("{}", user1.username);
}
调用这个函数并传入email和username直接就能创建一个结构体
结构体更新语法
实际场景中,常见一种情况就是,根据已有的结构实例,创建一个新的
就比如根据user1创建一个新的user2
let user2 = User {
active: user1.active,
username: user1.username,
email: String::from("another@example.com"),
sign_in_count: user1.sign_in_count,
};这种写法可以简化,因为除了email做了修改,其他都一样
简化版:
let user2 = User {
email: String::from("another@example.com"),
..user1
};结构体更新语法和赋值语句=很像,因此在代码中,user1的部分字段所有权被转移到了user2中,username字段发生了所有权转移,user1无法再被使用
为什么只有username发生了所有权转移?因为剩下两个字段都是简单类型,只用copy给user2就可以了
注意,虽然username的所有权转移给了user2,导致user1无法再被使用,但是不代表其他字段不能再被使用
let user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};
let user2 = User {
active: user1.active,
username: user1.username,
email: String::from("another@example.com"),
sign_in_count: user1.sign_in_count,
};
println!("{}", user1.active);
// 下面这行会报错
println!("{:?}", user1);//用调试格式打印整个结构体
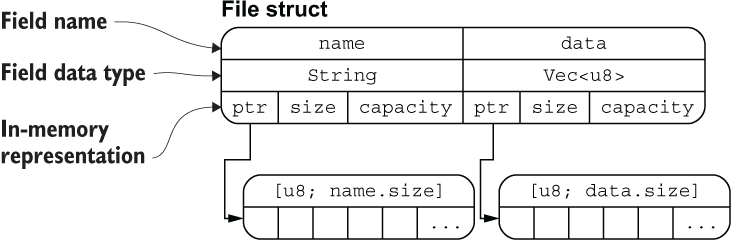
结构体的内存排列
#[derive(Debug)]
struct File {
name: String,
data: Vec<u8>,
}
fn main() {
let f1 = File {
name: String::from("f1.txt"),
data: Vec::new(),
};
let f1_name = &f1.name;
let f1_length = &f1.data.len();
println!("{:?}", f1);
println!("{} is {} bytes long", f1_name, f1_length);
}在这段代码中,上面定义的File结构体在内存中的排列方式如下
元组结构体
结构体必须要有名称,但结构体的字段可以没有名称,这种结构体长得很像元组,所以称为元组结构体:
struct Color(i32, i32, i32);
struct Point(i32, i32, i32);
let black = Color(0, 0, 0);
let origin = Point(0, 0, 0);
这个主要用在希望有一个整体名称,但是不关心字段名称,就比如Point元组结构体,可以用来描述3D点(x,y,z)形式的坐标点,无需给里面逐一命名成下x,y,z
单元结构体
这种结构体没有任何字段,只有个名字,长成下面这样
struct MyType;问题来了,他没有任何字段,存不了东西,那他是干嘛的?
作为标记类型/标签
比如你要实现一个 特征,但这个特征的实现不需要额外数据,只是提供一组函数:
struct MyHasher; // 单元结构体,只表示一种“算法”
impl MyHasher {
fn hash(s: &str) -> u64 {
// ...这里写算法...
0
}
}
fn main() {
let result = MyHasher::hash("hello");
}
MyHasher 本身不需要存任何状态,只是一个「名字 + 函数集合」
作为配置 / 策略占位——这个后续用到在学
作为「错误类型 / 自定义类型」但不需要额外信息
use std::fmt;
#[derive(Debug)]
struct MyError; // 不携带具体信息,只表示「发生了某种错误」
impl fmt::Display for MyError {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
write!(f, "something went wrong")
}
}这个目前了解一下就好